Rusty Russell, Hubertus Franke, Mathew Kirkwood에 의해 2.5.7에 도입된 futex 메커니즘은 사용자 애플리케이션을 위한 빠르고 가벼운 kernel-assisted locking primitive이다. 이것은 매우 빠른 비경합(uncontended) locking 획득 및 해제를 제공한다. futex 상태는 사용자 공간 변수(모든 플랫폼에서 부호 없는 32비트 정수)에 저장된다. atomic operation은 syscall의 오버헤드 없이 경합하지 않는(uncontended) 경우 futex의 상태를 변경하기 위해 사용된다. 경합(contended)하는 경우 커널을 호출하여 작업을 절전 모드로 전환하고 절전 모드를 해제한다. futex는 thread programming에서 일반적으로 사용되는 몇 가지 상호 배제(mutual exclusive) 구조의 기초이다. 여기에는 pthread mutex, condvar, semaphore, rwlock 및 장벽이 포함된다. 그들은 지난 몇 년 동안 많은 재건(reconstructive) 수술과 성형(cosmetic) 수술을 겪었고, 이제 그 어느 때보다 더 효율적이고, 더 기능적이며, 더 잘 문서화되었다.
Overview
futex를 직접 사용하는 애플리케이션 개발자는 거의 없지만, 나중에 제시된 개선 사항을 평가하기 위해서는 그 방법에 대한 대략적인 지식이 필요하다. 간단한 예를 들어, futex는 잠금 상태를 저장하고 잠금에서 작업을 차단하기 위한 커널 대기열(waitqueue)을 제공하는 데 사용될 수 있다. syscall 오버헤드를 최소화하려면 잠금이 중단되지 않은 경우 이 상태에서 원자 잠금(atomic lock)을 획득할 수 있어야 한다. 상태는 다음과 같이 정의할 수 있다:
0. unlocked 1. locked
locking을 획득하기 위해 atomic test-and-set 명령(예: cmpxchg())을 사용하여 0을 테스트하고 1로 설정할 수 있다. 이 경우, locking thread는 커널을 포함하지 않고 lock을 획득한다(그리고 커널은 이 futex가 존재한다는 것을 알지 못한다). 다음 스레드가 잠금을 획득하려고 할 때 0에 대한 테스트가 실패하고 커널이 관여해야 한다. 그런 다음 blocked thread는 futex_WAIT opcode와 함께 futex() 시스템 호출을 사용하여 futex에서 자체를 절전 모드로 전환하여 futex 상태 변수의 주소를 인수로 전달할 수 있다. 잠금을 해제하기 위해 소유자는 잠금 상태를 0(잠금 해제)으로 변경하고 FUTEX_WAKE opcode를 실행한다. FUTEX_WAKE opcode는 blocked thread를 사용자 공간으로 돌아가 잠금을 획득하려고 시도한다(위에서 설명한 대로). 이것은 최적화의 여지가 많은 명백한 사소한 예이다. Ulrich Drepper의 "futex are tricky"는 여전히 mutex와 같은 locking primitive를 구축하기 위해 futex를 사용하는 것에 대한 좋은 참조 문서이다. 여기에 제시된 예를 개선하기 위한 최적화뿐만 아니라 futex 사용과 관련된 많은 race condition을 언급하고 있다. 사용자 thread가 futex() 시스템 호출과 함께 커널에 호출할 때 futex 상태의 주소(uaddr), 수행할 opcode(op) 및 다양한 다른 인수를 전달한다. uaddr은 커널이 futex를 참조하는 고유한 "futex_key"를 생성하는 데 사용된다. thread가 FUTEX_WAIT와 같이 futex에서 차단을 요청할 때, "futex_q"가 생성되고 "futex_queues" 해시 테이블에 queuing된다. futex에서 차단된 모든 작업에 대해 하나의 futex_q가 존재하며, 많은 futex당 futex_q가 존재할 수 있다. 여러 개의 futex_key가 동일한 큐에 해시하기 때문에 futex_queue 자체("futex_q's"가 아닌 해시 테이블 목록)는 futex 간에 공유된다. 이러한 관계는 아래에 설명되어 있다:
대부분의 경우 사용자 공간 상태 변수를 사용하는 방법을 정의하는 정책은 없다. 응용 프로그램(또는 glibc와 같은 라이브러리)은 이 값을 사용하여 구현되는 locking 구조의 상태를 정의합니다. 이것은 부울 변수만큼 간단할 수 있지만(위의 예에서처럼) 최적화된 구현과 다른 locking 메커니즘은 더 복잡한 상태 값을 필요로 한다. 커널은 간단한 FUTEX_WAIT 및 FUTEX_WAKE 작업 외에도 잠금 구조의 상태에 대한 지식이 사용자 공간에서 가질 수 있는 것보다 더 많은 지식을 필요로 하는 priority inheritance(PI) 체인과 강력한 목록을 관리한다. PI 및 강력한 futex는 상태 변수와 관련된 사용자 정의 정책 규칙의 예외이다. 그들의 상태는 mutex의 잠긴 상태뿐만 아니라 소유자의 신원과 웨이터의 유무에 따라 달라진다. 이와 같이 futex 값은 소유자의 스레드 식별자(TID)와 보류 중인 소유자를 나타내는 비트로 정의된다. 이 정책을 사용하면 사용자 공간 atomic operation을 통해 중단되지 않은 경우 커널 호출을 피할 수 있다.
개선 사항
futex는 2.5.7에 처음 등장한 이후 소수의 개발자들로부터 수많은 개선을 보았다. 일부 주목할 만한 개선 사항에는 실시간 작업에 대한 우선 순위 기반 wakeup(Pierre Peifer)과 강력한 PI futex(Ingo Molnar 및 Thomas Gleixner)가 포함된다. 이러한 후자의 기능은 한동안 사용되어 왔으며 커널 메일링 목록에 대한 훌륭한 토론뿐만 아니라 LWN.net 에서도 적절하게 다루어졌다. 저자의 futex에 대한 시도는 2년반전 여기서 시작되었다. 희귀한 corner case와 race condition을 해결하기 위한 몇 가지 수정 사항 외에도, futex 코드는 이전의 기여 이후로 몇 가지 기능과 성능 향상을 보았다. futex 오버헤드를 줄이기 위해 상당한 노력을 기울였다. Eric Dumaze은 PTHREAD_PROCESS_PRIVATE pthread mutex에 대한 최적화로 private futex를 도입했다. private futex는 동일한 프로세스의 thread에서만 사용할 수 있다. 이들은 단순히 가상 주소로 서로 구별할 수 있는 반면, shared futex는 각 프로세스에서 서로 다른 가상 주소를 가지고 있어 커널이 고유한 식별을 위해 물리적 주소를 검색해야 한다. 이 최적화를 통해 private futex에 mmap_sem semaphore를 사용할 필요가 없으므로 시스템 전체의 경합이 줄어든다. 또한 private futex의 reference counting에 사용되는 atomic operation을 제거하여 SMP 머신에서 cache-line 바운스가 줄어든다. Glibc는 이제 기본적으로 private futex를 사용한다. Peter Ziljstra는 빠른 경로에서는 get_user_pages_fast()를 사용하고, (일반적인 상황에서는) get_user_pages()를 사용하며, 느린 경로 주변에서만 mmap_sem lock을 사용하도록 강하게 푸시함으로써 futex의 mmap_sem 의존성을 더욱 줄였다(2008년 9월). 이러한 변경은 kernel/futex.c에서 가상 메모리 관련 로직의 대부분을 제거하여 코드를 상당히 단순화하는 추가적인 이점이 있었다. 사용자 공간 주소에 의존하기 때문에 futex는 몇 가지 가능한 fault point을 부담한다. mmap_sem을 사용하는한, get_user()를 호출하기 전에 해제해야 했기 때문에 장애 로직이 복잡해졌다. mmap_sem 사용이 줄면서 작성자는 장애 로직을 크게 단순화하여(2009년 3월) 훨씬 더 읽기 쉬운 코드를 생성했다. bitset conditional wakeup은 glibc에서 최적화된 rwlock 구현을 가능하게 하기 위해 Thomas Gleixner(2008년 2월)에 의해 추가되었다. FUTEX_WAIT_BITSET 및 FUTEX_WAKE_BITSET을 사용하면 대기 시간에 동일한 bitset(또는 FUTEX_BITSET_MATCH_ANY와 같은 수퍼 세트)를 지정한 작업으로 wake up task를 제한하는 bitmask를 지정할 수 있다. PI futex의 도입 이후, pthread_cond_broadcast()의 glibc condvar 구현은 PI futex로의 대기열을 위한 지원이 부족하기 때문에 FUTEX_REQUEUE의 이점을 활용하지 않고 모든 대기자를 깨울 수밖에 없었다. 이것은 모든 waiter들이 사용자 공간으로 돌아가 lock을 얻기 위한 다툼을 벌이기 때문에 웨이크업 스톰(wakeup storm)이 발생한다. 또한 우선 순위가 가장 높은 작업이 먼저 잠금을 획득하는지 확인하지 못한다. 최근 커널(2.6.31-rt* 및 2.6.32-rc*)에는 이제 작성자의 FUTEX_CMP_REQUEUE가 추가되었다. PI 패치(2009년 4월)는 비PI futex에서 PI futex로 waiter를 대기시키기 위한 커널측 지원을 제공한다. Dinakar Guniguntala의 작업에서 glibc 패치를 통해 실시간 애플리케이션은 곧 guaranteed wakeup order와 더 적은 overall wake-up으로 pthread conditional variable을 사용할 수 있게 될 것이다.
자 이제는 뭐죠?
현재 구현된 kernel/mutex.c를 뒤로 하고, futex 개발자들은 다음 항목들을 고려하고 있다. (다음 단계에 처리할 항목을 담은 문서가 아직 나와 있지 않다.)
man page: 현재 man 페이지에는 새로운 futex 작업의 일부가 포함되어 있지 않다. 이들은 futex의 값에 대한 정책을 제안하고 있으며, 이로 인해 futex 사용에 대한 혼란이 발생하고 있다. 무엇보다도, 사용자 공간 futex() 정의가 /usr/include/linux/futex.h에서 제거되어 man 페이지가 불완전할 뿐만 아니라 부정확해졌다. futex 사용자는 syscall 인터페이스를 직접 사용해야 한다.
adaptive futex: futex의 스케줄링 오버헤드 중 일부는 커널에서 잠들기 전에 적절한 양의 spinning으로 줄일 수 있다. 그러나, futex가 그들의 상태를 사용자 공간에 노출시키기 때문에, 이 spinning은 현재 glibc의 adaptive mutex에서 수행되는 것처럼 사용자 공간에서도 수행될 수 있으며, 소유자가 실행 중인지 여부에 대한 지식이 없어도 spinning은 단순한 최대 재시도 루프로 감소된다.
interruptible futex: 대규모 독점 소프트웨어 프로젝트의 interrupt blocking lock operation에 관심이 있다. 현재 Futex 작업은 signal 발생 시 -EINTR을 사용자 공간으로 되돌리는 대신 자체적으로 재시작된다. futex는 FUTEX_INTRUSTIBLE로 플래그가 지정될 수 있으며, signal발생으로 인한 wakeup시 이 플래그는 시스템 호출을 다시 시작해야 하는지 또는 -ECANCELED를 사용자 공간으로 반환해야 하는지 결정한다. 이러한 기능을 pthread lock primitive로 공개하면 pthread 라이브러리에 대한 non-POSIX compliant 변경이 수반되지만 이는 전례가 없는 것은 아니다.
scalability enhancement: LKML은 NUMA에 최적화된 해시 테이블뿐만 아니라 비공개 해시 테이블에 대해서도 논의되어 왔다. futex 해시 테이블은 모든 프로세스에서 공유되며 특히 대규모 시스템에서 실제 오버헤드로 이어질 수 있는 spinlock에 의해 보호된다. 이 오버헤드는 시스템이 NUMA 노드에서 파티셔닝되거나 private futex를 단독으로 사용하는 프로세스에 대해서는 적용되지 않는다.
futex test suite: 작성자가 futex 기능을 검증하기 위해 전체 테스트 제품군에 대한 요구 사항 목록을 작성하고 있다. 이 test suite는 향후 개발을 위한 regression suite 역할을 할 것이다. futex로 가능한 많은 corner case와 misuse case는 test suite를 복잡하게 만들고 설계에 문제를 제기한다.
Acknowledgement
나는 John Stultz, Will Schmidt, Paul McKenney, Nivedita Singhvi, 그리고 물론 Jon Corbet에게 감사를 표하고 싶다. 그의 리뷰는 이 기사를 그렇지 않았을 때보다 훨씬 더 읽기 쉽고 완전하게 만들었다.
커널은 유용한 데이터 구조를 구현하기위한 많은 라이브러리 루틴을 포함합니다. 그중 두 가지 유형의 tree가 있습니다 : radix tree와 red-black tree. 이 기사에서는 radix tree API를 살펴볼 것입니다. red-black tree는 나중에.
The kernel includes a number of library routines for the implementation of useful data structures. Among those are two types of trees: radix trees and red-black trees. This article will have a look at the radix tree API, with red-black trees to follow in the future.
Wikipedia는radix tree 항목을 가지고 있지만 Linux radix tree는 잘 설명되어 있지 않습니다. Linux radix tree는 (포인터) 값이 (긴) 정수 키와 연관 될 수있는 메커니즘입니다. 그것은 저장면에서 상당히 효율적이며, 조회에서 꽤 빠릅니다. 또한 Linux 커널의 radix tree에는 특정 항목과 태그를 연결하는 기능을 비롯하여 커널 관련 요구 사항에 따라 일부 기능이 있습니다.
Wikipedia hasa radix tree article, but Linux radix trees are not well described by that article. A Linux radix tree is a mechanism by which a (pointer) value can be associated with a (long) integer key. It is reasonably efficient in terms of storage, and is quite quick on lookups. Additionally, radix trees in the Linux kernel have some features driven by kernel-specific needs, including the ability to associate tags with specific entries.
위쪽 치즈 다이어그램은 Linux radix tree의 leaf node를 보여줍니다. 노드는 다수의 슬롯을 포함하며, 각각의 슬롯은 트리 작성자가 관심을 갖는 포인터를 포함 할 수 있습니다. 빈 슬롯은 NULL 포인터를 포함합니다. 이 tree들은 상당히 넓습니다 - 2.6.16-rc 커널에서는 각 radix tree node에 64 개의 슬롯이 있습니다. 슬롯은 (긴) 정수 키의 일부로 인덱싱됩니다. 가장 높은 키 값이 64보다 작으면 전체 트리를 단일 노드로 나타낼 수 있습니다. 그러나 일반적으로 키의 다소 큰 세트가 사용됩니다. 그렇지 않으면 간단한 배열을 사용할 수 있습니다. 그래서 더 큰 tree는 다음과 같이 보일 것입니다 :
The cheesy diagram on the right shows a leaf node from a Linux radix tree. The node contains a number of slots, each of which can contain a pointer to something of interest to the creator of the tree. Empty slots contain a NULL pointer. These trees are quite broad - in the 2.6.16-rc kernels, there are 64 slots in each radix tree node. Slots are indexed by a portion of the (long) integer key. If the highest key value is less than 64, the entire tree can be represented with a single node. Normally, however, a rather larger set of keys is in use - otherwise, a simple array could have been used. So a larger tree might look something like this:
이 tree는 3 level deep입니다. 커널이 특정 키를 검색 할 때 루트 노드에서 적절한 슬롯을 찾기 위해 가장 중요한 6 비트가 사용됩니다. 다음 6 비트는 중간 노드의 슬롯을 인덱싱하고, 최하위 6 비트는 실제 값을 가리키는 포인터를 포함하는 슬롯을 나타냅니다. 자식이 없는 노드는 트리에 존재하지 않으므로 radix tree가 성긴(sparse) tree에 대한 효율적인 저장소를 제공 할 수 있습니다.
This tree is three levels deep. When the kernel goes to look up a specific key, the most significant six bits will be used to find the appropriate slot in the root node. The next six bits then index the slot in the middle node, and the least significant six bits will indicate the slot containing a pointer to the actual value. Nodes which have no children are not present in the tree, so a radix tree can provide efficient storage for sparse trees.
Radix tree는 메인 라인 커널 트리에 몇 명의 사용자가 있습니다. PowerPC 아키텍처는 트리를 사용하여 실제 IRQ 번호와 가상 IRQ 번호를 매핑합니다. NFS 코드는 관련 아이 노드 구조에 트리를 첨부하여 미해결 요청을 추적합니다. 그러나 radix tree의 가장 널리 사용되는 것은 메모리 관리 코드에 있습니다. 백업 저장소를 추적하는 데 사용되는 address_space 구조에는 해당 매핑과 연결된 코어 페이지를 추적하는 radix tree가 있습니다. 무엇보다도 이 트리를 사용하면 메모리 관리 코드가 더럽거나 쓰기 저장중인 페이지를 빠르게 찾을 수 있습니다.
Radix trees have a few users in the mainline kernel tree. The PowerPC architecture uses a tree to map between real and virtual IRQ numbers. The NFS code attaches a tree to relevant inode structures to keep track of outstanding requests. The most widespread use of radix trees, however, is in the memory management code. The address_space structure used to keep track of backing store contains a radix tree which tracks in-core pages tied to that mapping. Among other things, this tree allows the memory management code to quickly find pages which are dirty or under writeback.
커널 데이터 구조에서 일반적인 것처럼 기수를 선언하고 초기화하는 두 가지 모드가 있습니다.
As is typical with kernel data structures, there are two modes for declaring and initializing radix trees:
첫번째 형식은 지정된 이름으로 radix tree를 선언하고 초기화합니다. 두번째 형식은 런타임에 초기화를 수행합니다. 두 경우 모두 메모리 할당이 수행되는 방법을 코드에 알려주기 위해 gfp_mask 를 제공해야합니다. radix tree 연산 (특히 삽입)이 원자적 컨텍스트에서 수행되는 경우, 주어진 마스크는 GFP_ATOMIC 이어야합니다.
The first form declares and initializes a radix tree with the given name; the second form performs the initialization at run time. In either case, a gfp_mask must be provided to tell the code how memory allocations are to be performed. If radix tree operations (insertions, in particular) are to be performed in atomic context, the given mask should be GFP_ATOMIC.
항목을 추가하고 제거하는 기능은 간단합니다.
The functions for adding and removing entries are straightforward:
int radix_tree_insert(struct radix_tree_root *tree, unsigned long key, void *item); void *radix_tree_delete(struct radix_tree_root *tree, unsigned long key);
radix_tree_insert ()를 호출하면, 지정된 트리에 지정된 항목이 삽입됩니다 (키와 관련된 ). 이 작업에는 메모리 할당이 필요할 수 있습니다. 할당이 실패하면 삽입이 실패하고 반환 값은 -ENOMEM이 됩니다. 이 코드는 기존 항목을 덮어 쓰지 않습니다. 트리에 키가 이미 존재하면 radix_tree_insert () 는 -EEXIST 를 반환 합니다 . 성공시 반환 값은 0입니다. radix_tree_delete () 는 tree에 key 와 연관된 항목을 제거하고, 해당 항목에 대한 포인터를 반환합니다.
A call to radix_tree_insert() will cause the given item to be inserted (associated with key) in the given tree. This operation may require memory allocations; should an allocation fail, the insertion will fail and the return value will be -ENOMEM. The code will refuse to overwrite an existing entry; if key already exists in the tree, radix_tree_insert() will return -EEXIST. On success, the return value is zero. radix_tree_delete() removes the item associated with key from tree, returning a pointer to that item if it was present.
Radix tree에 항목을 넣지 못하는 것이 심각한 문제가 될 수있는 상황이 있습니다. 이러한 상황을 피하기 위해 한 쌍의 특수 기능이 제공됩니다.
There are situations where failure to insert an item into a radix tree can be a significant problem. To help avoid such situations, a pair of specialized functions are provided:
int radix_tree_preload(gfp_t gfp_mask); void radix_tree_preload_end(void);
이 함수는 다음 radix tree 삽입이 실패하지 않도록 보장하기 위해, 주어진 gfp_mask를 사용하여 충분한 메모리를 할당하려고합니다. 할당된 구조는 CPU 당 변수에 저장됩니다. 즉, 호출 기능이 예약하거나 다른 프로세서로 이동할 수 있기 전에 삽입 기능을 수행해야 합니다. 이를 위해, radix_tree_preload () 는 성공적 일 때, preemption이 비활성화 된 상태로 돌아갑니다. 호출자는 결국 radix_tree_preload_end () 를 호출하여 선점권을 다시 활성화해야합니다. 실패하면 -ENOMEM 이 반환되고 선점이 비활성화 되지 않습니다.
This function will attempt to allocate sufficient memory (using the given gfp_mask) to guarantee that the next radix tree insertion cannot fail. The allocated structures are stored in a per-CPU variable, meaning that the calling function must perform the insertion before it can schedule or be moved to a different processor. To that end, radix_tree_preload() will, when successful, return with preemption disabled; the caller must eventually ensure that preemption is enabled again by calling radix_tree_preload_end(). On failure, -ENOMEM is returned and preemption is not disabled.
radix tree 검색은 몇 가지 방법으로 수행 할 수 있습니다.
Radix tree lookups can be done in a few ways:
void *radix_tree_lookup(struct radix_tree_root *tree, unsigned long key); void **radix_tree_lookup_slot(struct radix_tree_root *tree, unsigned long key); unsigned int radix_tree_gang_lookup(struct radix_tree_root *root, void **results, unsigned long first_index, unsigned int max_items);
가장 간단한 형식인 radix_tree_lookup () 은 트리에서 key 를 찾고 연관된 항목을 반환합니다 (실패 할 경우 NULL ). 대신 radix_tree_lookup_slot () 은 항목에 대한 포인터가 있는 슬롯에 대한 포인터를 반환합니다. 호출자는 포인터를 변경하여 새 항목을 키와 연관시킬 수 있습니다. 그러나 항목이 없으면 radix_tree_lookup_slot () 은 슬롯을 만들지 않으므로 radix_tree_insert () 대신 사용할 수 없습니다.
The simplest form, radix_tree_lookup(), looks for key in the tree and returns the associated item (or NULL on failure). radix_tree_lookup_slot() will, instead, return a pointer to the slot holding the pointer to the item. The caller can, then, change the pointer to associate a new item with the key. If the item does not exist, however, radix_tree_lookup_slot() will not create a slot for it, so this function cannot be used in place of radix_tree_insert().
마지막으로, radix_tree_gang_lookup ()을 호출하면 first_index 에서 시작하는 키 값이 오름차순으로 결과의 max_items 항목까지 반환됩니다. 돌려 주어지는 아이템의 수는 요구한 것보다 적을 수 있습니다만, 짧은 반환 (제로 이외)은 트리에 값이 없는 것을 의미하지 않습니다.
Finally, a call to radix_tree_gang_lookup() will return up to max_items items in results, with ascending key values starting at first_index. The number of items returned may be less than requested, but a short return (other than zero) does not imply that there are no more values in the tree.
radix tree 함수는 내부적으로 어떤 종류의 잠금(locking)도 수행하지 않는다는 것을 알아야합니다. 여러 스레드가 트리를 손상시키거나 다른 종류의 불쾌한 경쟁 조건에 빠지지 않도록 하는 것은 호출자의 몫입니다. Nick Piggin은 현재 free 트리 노드를 읽기 위해 copy-update를 사용하는 패치를 배포하고 있습니다. 이 패치는 (1) 결과 포인터가 원자적 컨텍스트에서만 사용되며 (2) 호출 코드가 자체 경쟁 조건 생성을 피하는 한 잠금없이 조회 작업을 수행 할 수 있습니다. 그러나 패치가 병합 될 예정인지 명확하지 않습니다.
One should note that none of the radix tree functions perform any sort of locking internally. It is up to the caller to ensure that multiple threads do not corrupt the tree or get into other sorts of unpleasant race conditions. Nick Piggin currently has a patch circulating which would use read-copy-update to free tree nodes; this patch would allow lookup operations to be performed without locking as long as (1) the resulting pointer is only used in atomic context, and (2) the calling code avoids creating race conditions of its own. It is not clear when that patch might be merged, however.
radix tree 코드는 "태그"라는 기능을 지원합니다. 특정 비트가 트리의 항목에 설정 될 수 있습니다. 태그는 예를 들어 더럽거나(dirty) 쓰기 저장 상태(under write back)인 메모리 페이지를 표시하는 데 사용됩니다. 태그 작업을 위한 API는 다음과 같습니다.
The radix tree code supports a feature called "tags," wherein specific bits can be set on items in the tree. Tags are used, for example, to mark memory pages which are dirty or under writeback. The API for working with tags is:
void *radix_tree_tag_set(struct radix_tree_root *tree, unsigned long key, int tag); void *radix_tree_tag_clear(struct radix_tree_root *tree, unsigned long key, int tag); int radix_tree_tag_get(struct radix_tree_root *tree, unsigned long key, int tag);
radix_tree_tag_set () 은 key에 의해 인덱싱 된 항목에 주어진 태그 를 설정합니다; 존재하지 않는 키에 태그를 설정하려고하면 오류가 발생합니다. 반환 값은 태그가 추가 된 항목에 대한 포인터입니다. 태그는 임의의 정수처럼 보이지만 현재 작성된 코드는 최대 두 개의 태그를 허용합니다. 0 또는 1 이외의 태그 값을 사용하면 일부 바람직하지 않은 위치에서 메모리가 자동으로 손상됩니다; 자신을 경고한다고 생각해보십시오.
radix_tree_tag_set() will set the given tag on the item indexed by key; it is an error to attempt to set a tag on a nonexistent key. The return value will be a pointer to the tagged item. While tag looks like an arbitrary integer, the code as currently written allows for a maximum of two tags. Use of any tag value other than zero or one will silently corrupt memory in some undesirable place; consider yourself warned.
태그는 radix_tree_tag_clear () 로 제거 할 수 있습니다; 다시 한번 얘기하자면, 반환 값은 태그(또는 untag)가 붙은 항목에 대한 포인터입니다. radix_tree_tag_get () 함수는 키에 의해 색인된 항목이 주어진 태그 세트를 가지고 있는지를 검사 할 것이다. key 가 없으면 반환 값은 0이고, key 가 있지만 태그가 설정되어 있지 않으면 -1, 그렇지 않으면 +1입니다. 그러나, 이 기능은 현재 소스 코드에서 주석으로 처리되어 있으므로 트리 코드에서는 이를 사용하지 않습니다.
Tags can be removed with radix_tree_tag_clear(); once again, the return value is a pointer to the (un)tagged item. The function radix_tree_tag_get() will check whether the item indexed by key has the given tag set; the return value is zero if key is not present, -1 if key is present but tag is not set, and +1 otherwise. This function is currently commented out in the source, however, since no in-tree code uses it.
태그를 쿼리하는 데는 두 가지 다른 기능이 있습니다.
There are two other functions for querying tags:
int radix_tree_tagged(struct radix_tree_root *tree, int tag); unsigned int radix_tree_gang_lookup_tag(struct radix_tree_root *tree, void **results, unsigned long first_index, unsigned int max_items, int tag);
radix_tree_tagged () 는 트리의 항목에 주어진 태그가 있을 경우 0이 아닌 값을 반환합니다. 주어진 태그가 있는 항목의 목록은 radix_tree_gang_lookup_tag ()를 통해 얻을 수 있습니다.
radix_tree_tagged() returns a non-zero value if any item in the tree bears the given tag. A list of items with a given tag can be obtained with radix_tree_gang_lookup_tag().
결론적으로, radix tree API의 또 다른 흥미로운 점은 radix tree를 파기 할 수있는 기능이 없다는 것입니다. 분명히 radix tree가 영원히 지속될 것이라고 가정합니다. 실제로는, radix tree에서 모든 항목을 삭제하면 루트 노드 이외의 모든 메모리가 해제되어 정상적으로 처리 될 수 있습니다.
In concluding, we can note one other interesting aspect of the radix tree API: there is no function for destroying a radix tree. It is, evidently, assumed that radix trees will last forever. In practice, deleting all items from a radix tree will free all memory associated with it other than the root node, which can then be disposed of normally.
When asked which of the changes in 2.6.24 was most likely to create problems, an informed observer might well point at the i386/x86_64 merger. As it happens, that large patch set has gone in with relatively few hitches, but a rather smaller change has created quite a bit of fallout. The change in question is the updated API for the management of scatterlists, which are used in scatter/gather I/O. This work broke a number of in-tree drivers, so it seems likely to affect a lot of out-of-tree code as well.
Scatter / gather I/O는 시스템이 실제 메모리에 분산되어있는 버퍼에 대해 DMA I / O 작업을 수행 할 수있게합니다. 예를 들어, 사용자 공간에서 생성 된 대형 (다중 페이지) 버퍼의 경우를 생각해보십시오. 응용 프로그램은 연속적인 범위의 가상 주소를 보지만 그 주소 뒤에 있는 물리적 페이지는 거의 서로 인접하지 않습니다. 단일 I / O 작업에서 해당 버퍼를 장치에 기록하려면 다음 두 가지 중 하나를 수행해야합니다. (1) 데이터를 물리적으로 인접한 버퍼에 복사해야하거나 (2) 장치가 물리적 주소 및 길이 목록을 사용하여 각 세그먼트에서 올바른 양의 데이터를 가져옵니다. Scatter / gatter I/O는, 연속적인 버퍼로 데이터를 복사 할 필요를 제거함으로써, I/O 작업의 효율성을 크게 높일 수있을뿐만 아니라 물리적으로 연속적인 대형 버퍼의 생성이 처음에는 문제가 될 수 있다는 문제를 해결할 수 있습니다.
Scatter/gather I/O allows the system to perform DMA I/O operations on buffers which are scattered throughout physical memory. Consider, for example, the case of a large (multi-page) buffer created in user space. The application sees a continuous range of virtual addresses, but the physical pages behind those addresses will almost certainly not be adjacent to each other. If that buffer is to be written to a device in a single I/O operation, one of two things must be done: (1) the data must be copied into a physically-contiguous buffer, or (2) the device must be able to work with a list of physical addresses and lengths, grabbing the right amount of data from each segment. Scatter/gather I/O, by eliminating the need to copy data into contiguous buffers, can greatly increase the efficiency of I/O operations while simultaneously getting around the problem that the creation of large, physically-contiguous buffers can be problematic in the first place.
커널 내에서, scatter / gather DMA 연산에 사용될 버퍼는 <linux / scatterlist.h>에 정의 된 하나 이상의 scatterlist 구조의 배열로 표현됩니다. 이 배열은 전통적으로 단일 페이지 내에 들어가도록 제한되어있어 분산 / 수집 작업에 최대 길이를 부여합니다. 이 한계는 하이 엔드 시스템에서 병목 현상이되는 것으로 나타났습니다. 그렇지 않으면 대용량 버퍼 (일반적으로 디스크 장치간에)를 전송할 때 이점이 있습니다. 결과적으로 그 한계를 극복 할 수있는 방안이 모색되고 있습니다. 간혹 mailing list에 나타나는 대용량 블록 크기 패치가 한 가지 방법입니다. 그러나 커널을 2.6.24 커널로 만들었던 해법은 Scatter / gatter list의 길이를 묶어서(chained) 제거하는 것입니다.
Within the kernel, a buffer to be used in a scatter/gather DMA operation is represented by an array of one or more scatterlist structures, defined in <linux/scatterlist.h>. This array has traditionally been constrained to fit within a single page, which imposes a maximum length on scatter/gather operations. That limit has proved to be a bottleneck on high-end systems, which could otherwise benefit from transferring very large buffers (usually to and from disk devices). As a result, there has been a search for ways to get around that limit; the large block size patches which occasionally surface on the mailing lists are one approach. But the solution which has made it into the 2.6.24 kernel is to remove the limit on the length of scatter/gather lists by allowing them to be chained.
Chained Scatter / gatter list는 둘 이상의 페이지로 구성 될 수 있으며 해당 페이지도 실제 메모리에 흩어질 수 있습니다. 이 체인(chaining)이 완료되면 버퍼 포인터의 하위 비트 두 개를 사용하여 체인 항목과 목록의 끝을 표시합니다. 이 사용법은 드라이버 코드에서 걱정할 필요가 있는 것이 아니지만 특수 bit와 체인 pointer가 있으면 드라이버가 scatter list에서 작동하는 방식을 일부 변경해야합니다.
A chained scatter/gather list can be made up of more than one page, and those pages, too, are likely to be scattered throughout physical memory. When this chaining is done, a couple of low-order bits in the buffer pointer are used to mark chain entries and the end of the list. This usage is not something which driver code needs to worry about, but the existence of special bits and chain pointers forces some changes to how drivers work with scatterlists.
연결(chaining)을 수행하지 않는 드라이버는 일반적으로 kcalloc () 또는 일부 호출을 통해 scatterlist array를 일반적인 방식으로 할당합니다. 2.6.23 이전에는 초기화 단계가 필요하지 않았으며, 아마도 전체 배열을 초기화하지 않았습니다. 그러나 그것은 바뀌었습니다. 드라이버는 다음과 같이 scatterlist array를 초기화해야합니다:
Drivers which do not perform chaining will allocate their scatterlist arrays in the usual way - usually through a call to kcalloc() or some such. Prior to 2.6.23, there was no initialization step required, beyond, perhaps, zeroing the entire array. That has changed, however; drivers should now initialize a scatterlist array with:
void sg_init_table(struct scatterlist *sg, unsigned int nents);
여기서 sg 는 할당 된 배열을 가리키고, nents 는 할당 된 scatter/gather entry들의 갯수입니다.
Here, sg points to the allocated array, and nents is the number of allocated scatter/gather entries.
이전과 마찬가지로, 드라이버는 버퍼의 세그먼트를 반복하여 각각에 대해 하나의 scatterlist 항목을 설정해야합니다. 그러나 더 이상 페이지 포인터를 직접 설정할 수는 없습니다: 그 포인터는 2.6.24에 존재하지 않습니다. 대신, scatterlist 항목을 설정하는 일반적인 방법은 다음 중 하나입니다:
As before, a driver should loop through the segments of the buffer, setting one scatterlist entry for each. It is no longer possible to set the page pointer directly, however: that pointer does not exist in 2.6.24. Instead, the usual way to set a scatterlist entry will be with one of:
void sg_set_page(struct scatterlist *sg, struct page *page, unsigned int len, unsigned int offset); void sg_set_buf(struct scatterlist *sg, const void *buf, unsigned int buflen);
2.6.24 scatterlist는 또한 목록의 끝 부분에 명시적으로 표시해야합니다. 이 표시는 sg_init_table () 이 호출 될 때 수행되므로, 드라이버는 일반적으로 명시적으로 끝을 표시하지 않아도됩니다. I/O 작업이 목록에 할당된 모든 항목을 사용하지 않으면, 드라이버는 최종 세그먼트를 다음처럼 표시해야합니다:
2.6.24 scatterlists also require that the end of the list be explicitly marked. This marking is performed when sg_init_table() is called, so drivers will not normally have to mark the end explicitly. Should the I/O operation not use all of the entries which were allocated in the list, though, the driver should mark the final segment with:
void sg_mark_end(struct scatterlist *sg, unsigned int nents);
여기서 nents 는 scatterlist의 유효한 항목 수입니다.
Where nents is the number of valid entries in the scatterlist.
scatterlist가 매핑 된 후 ( dma_map_sg () 와 같은 함수를 사용하여), 드라이버는 결과 DMA 주소를 하드웨어에 프로그래밍해야합니다. 배열을 단계적으로 실행하는 이전 접근 방식은 더 이상 작동하지 않습니다. 대신 드라이버는 다음을 사용하여 scatterlist의 다음 항목으로 이동해야합니다:
After the scatterlist has been mapped (with a function like dma_map_sg()), the driver will need to program the resulting DMA addresses into the hardware. The old approach of just stepping through the array will no longer work; instead, a driver should move on to the next entry in a scatterlist with:
반환 값은 처리 할 다음 항목이되거나 목록의 끝에 도달하면 NULL이 됩니다. 또한 전체 scatterlist를 반복하는 데 사용할 수있는 for_each_sg () 매크로가 있습니다. 일반적으로 다음과 같은 코드에서 사용됩니다:
The return value will be the next entry to process - or NULL if the end of the list has been reached. There is also a for_each_sg() macro which can be used to iterate through an entire scatterlist; it will typically be used in code which looks like:
int i; struct scatterlist *list, *sgentry; /* Fill in list and pass it to dma_map_sg(). Then... */ for_each_sg(i, list, sgentry, nentries) { program_hw(device, sg_dma_address(sgentry), sg_dma_len(sgentry)); }
chaining feature를 이용하려는 드라이버는 조금만 더 작업해야합니다. scatterlist의 각 조각은 독립적으로 할당되어야하며 그 조각은 다음과 함께 체인(chained)되어야합니다.
Drivers which wish to take advantage of the chaining feature must do just a little more work. Each piece of the scatterlist must be allocated independently, then those pieces must be chained together with:
void sg_chain(struct scatterlist *prv, unsigned int prv_nents, struct scatterlist *next);
이 호출은 scatterlist 엔트리 prv [nents] 를 next 에 대한 체인 링크로 변환합니다. 목록이 채워지는 동안 연결이 완료되면, prv 에는 prv_nents-1 세그먼트가 저장되어 있어야합니다. 또는 드라이버는 미리 목록의 조각을 함께 묶을 수 있습니다 (각 체인 링크마다 하나의 항목을 할당하는 것을 기억하십시오). 그런 다음 sg_next () 를 사용하여 체인 링크가 어디에 있는지 걱정할 필요없이 목록을 채웁니다.
This call turns the scatterlist entry prv[nents] into a chain link to next. If the chaining is done while the list is being filled, prv should have no more than prv_nents-1 segments stored into it. Alternatively, a driver can chain together the pieces of the list ahead of time (remembering to allocate one entry for each chain link), then use sg_next() to fill the list without the need to worry about where the chain links are.
이 글을 쓰는 시점에서,이 API는 in-tree 드라이버와 관련된 문제에 대응하여 계속 진화하고 있습니다. 2.6.24 릴리즈 이전에는 더 이상의 실질적인 변경이 이루어질 것 같지 않지만, 변경이 될 수도 있습니다.
As of this writing, this API is still evolving in response to issues which have come up with in-tree drivers. It seems unlikely that any more substantial changes will be made before the 2.6.24 release, but surprises are always possible.
mtime은 file 내용이 수정된 마지막 시간을 가리킵니다. 최근에 mtime을 자동으로 update하지 않도록 하는 patch가 올라왔습니다. 이는 Ceph filesystem(http://lwn.net/Articles/258516/)과 같이 mtime을 사용하지 않는 경우, 성능을 향상시키는 효과가 있습니다. 하지만, NFS나 system backup과 같이 mtime을 이용하는 경우, 이 option은 매우 위험한 선택입니다. 그리고, system suspend와 같은 상황에서는 더욱 복잡해집니다.
어쨌든 O_NOMTIME option은 손쉽게 system 성능을 개선할 수 있습니다만, application 개발자가 sync하는 것을 잊는 경우, file system에 손상을 줄 수 있습니다.
persistent memory(or non-volatile memory), 쉽게 NOR flash를 생각하면될 것같습니다. SSD에 대해서 direct-access를 하는 경우도 있을지도.
어쨌든 이 유형의 h/w는 cpu에서 직접 접근가능하다.라는 이점이 있어서 이것을 이용할 수 있는 방법에 대한 논의를 간단히 다룬 내용입니다.
단순하게 ROM처럼 page로 분할해서 mapping해버리면 1TB가 넘는 경우, 관리하는 데만많은 memory를 사용하므로 좋지 않습니다. 이에... 1. persistent memory에 대해서 Page Frame Number(PFN)을 사용. - http://lwn.net/Articles/643437/ - by Dan Williams - page structure를 손대서 persistent memory인 경우, page가 아닌 PFN을 사용 2. Directly mapped persistent memory page cache - http://lwn.net/Articles/644114/ - by Ingo Molnar - page structure를 일반 memory가 아닌 persistent memory에 저장
block device에서 data를 access하려면 data를 page cache에 올린 다음에 읽습니다. file system도 block device에 접근하기 위해서 page cache를 이용하지요. 그런데, 직접 접근가능한 block device(간단한 예로 RAM이나 NOR Flash)위에 file system을 올려서 사용한다면? page cache가 없는 편이 성능에 도움이 되는 상황도 있습니다.
이런 시도는 2005년 즈음에 ext2 file system에 XIP(excute in-place)를 구현하기도 했습니다. 위 기사는 DAX(directy access)라는 새로운 시도에 대한 얘기입니다.
ramfs와 같은 ram-based file system을 쓰는 것도 하나의 방법이긴 하지만, 전원이 나가면 사라지는 RAM이 아닌 Flash와 같은 NVM(non-volatile memory)위에서 NVM 전용 file system이 아닌 ext4와 같은 일반 file system에서 성능 향상을 시도하는 것으로 알고 있습니다. kernel 4.0부터 ext4에서는 지원된다고 합니다.
TCP 연결의 초기 packet에는 해당 IP를 운영하는 system의 정보를 많이 담고 있습니다. 문제는 그 정보는 kernel 내부에 있다는 점. 그 정보를 user-space에 있는 server들이 얻을 수 있도록 해주는 patch가 최근 merge되었다고 합니다.
setsockopt() 함수를 TCP_SAVE_SYN option과 같이 listen() 함수 이전에 호출한 다음, accept()로 얻은 socket에 대해서 getsockopt() 함수를 TCP_SAVED_SYN option으로 얻은 TCP/IP header를 통해서 정보를 얻을 수 있다고 합니다.
network 혼잡제어 알고리즘(network congestion-control algorithm)중 하나로 CAIA delay gradient(CDG)라는 것이 제안되었답니다.
기존 알고리즘은 packet loss가 발생하기 시작하면 network이 혼잡한 것으로 인식하고, packet 전송 갯수를 줄이는데 비해 CDG는 round-trip time(RTT)를 이용합니다. 구체적으로는 RTT_min값이 증가하면 network의 혼잡도가 증가하는 것으로 인지한다고 합니다.
기존 알고리즘과 CDG와 공존과 같은 문제를 풀어야 적용될 것같습니다. CDG에 대한 자세한 내용은 http://caia.swin.edu.au/cv/dahayes/content/networking2011-cdg-preprint.pdf 를 보시면 됩니다.
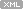

![[radix tree node]](https://lh3.googleusercontent.com/5BwAQjgVpaXdcE10DMl0iYlqlqRHhBC6sQeavVZon73iH2AWm79B7hYaRUCowVYrh1KUo0SiN3NPNPDkz-O5X8I0mBxK4iaL2TZD5PGhfGi9bfnSKQDI4SLCAhxV3y0H5XW0MwXJ)
![[big radix tree]](https://lh4.googleusercontent.com/9e1K9iWvvcv6LAVsQabi6Uj8778DzSTyWp_7ReOxfL2H0jRO5AjkN1yeXUNlKExNZJsi3xJGbYVr0N3BN12dsG6zlkTx7TjIPiyEdkEjFwYK6CdVV3x5ZUT1BGxQeLGo-YRCtj0T)

